なぜJavaScriptのfetchはawaitを2回しないとレスポンスを取れないのか
JavaScriptの fetch を使ったことがある人なら、こんなコードを書いたことがあると思います。
const resp = await fetch("https://api.example.com/data");const data = await resp.json();await を2回書いているのが気になったことはありませんか?1回の await で一気にレスポンスボディまで取れたら楽なのに、と思ったことはないでしょうか。
とある休日の午前中、いつものようにYouTube上でライブコーディング動画を見ていました1。そこで配信者の方が、fetchを使ってレスポンスボディを取得する際に2回目のawaitが必要であることに対して、「なんでfetchはこんなにめんどくさいんだろう」と言っていました。言われてみると、確かにめんどくさいような気もします。
この記事では、なぜ fetch がこのような設計になっているのかをいろいろな観点から掘り下げてみます。
fetch の使い方おさらい
まずはJavaScriptのfetchの基本的な使い方を確認してみます。
// 1回目の await: レスポンスヘッダが届くまで待つconst resp = await fetch("https://api.example.com/users");
// この時点でヘッダにはアクセスできるconsole.log(resp.status);console.log(resp.headers.get("Content-Type"));
// 2回目の await: レスポンスボディを読み取るconst users = await resp.json();fetch() が返す Promise は、レスポンスヘッダが届いた時点で解決されます。この時点ではまだボディは読み取れていません。ボディを読むには .json() や .text(), bytes() といったメソッドを呼ぶ必要があり、これらも Promise を返すので再度 await が必要になります。
もし await が1回で済む設計だったら
「1回の await でヘッダもボディも全部取れたら便利なのに」と思うこともあると思います。以下のようなイメージです。
// 仮想的なAPI: 1回のawaitでボディまで取得const { headers, body } = await fetch("https://api.example.com/users");この仮想的なAPIだとどのような問題が出てくるのかを考えてみます。
問題1: 巨大なレスポンスボディ
レスポンスボディが数GBあるファイルだったらどうでしょうか?
1回の await でボディまで取得する設計だと、全データがメモリに読み込まれるまで待つことになります。時間がかかるだけでなく、メモリを大量に消費してしまいます。
現在の設計なら、ヘッダを見てからボディをストリームとして少しずつ処理できます。
const resp = await fetch("https://example.com/huge-file.zip");
// Content-Length を確認してから処理を決められるconst size = resp.headers.get("Content-Length");console.log(`file size = ${size} bytes`);
// ストリームとして少しずつ処理const reader = resp.body.getReader();while (true) { const { done, value } = await reader.read(); if (done) break; // value (Uint8Array) を少しずつ処理 // 例えば、ローカルファイルに書き込んでいくなど}問題2: 終わらないストリーミングレスポンス
レスポンスボディが永遠に終わらないケースもあります。
代表例が Server-Sent Events (SSE) です。SSE はサーバーからクライアントへリアルタイムにデータをプッシュする仕組みで、
ChatGPT や
Claude の API でストリーミングレスポンスを受け取るときにも使われています。
// SSE エンドポイントへのリクエストconst resp = await fetch("https://api.example.com/events");
// ストリームとして読み取るconst reader = resp.body.getReader();const decoder = new TextDecoder();
while (true) { const { done, value } = await reader.read(); if (done) break;
const chunk = decoder.decode(value, { stream: true }); console.log("received chunk:", chunk); // data: {"message": "Hello"} // data: {"message": "World"} // ...(サーバーが送り続ける限り続く)}SSE のレスポンスは、サーバーが接続を閉じるか、クライアントが明示的に中断するまで終わりません。
もし1回の await でヘッダとボディを全部取得するようになっていたら、この await はかなり長い間完了しないことになってしまいます。
JavaScript エコシステムの HTTP クライアントライブラリ
さて、fetch は「2回 await」の設計になっていますが、npm にある他の HTTP クライアントライブラリはどのような設計になっているかも見てみます。
axios
axios では1回の
await でレスポンスボディまで取得できます。
import axios from "axios";
const resp = await axios.get("https://api.example.com/users");// resp.data にはすでにパース済みの JSON オブジェクトが入っているconsole.log(resp.data);fetch と違う設計ですね。
では大きなファイルのダウンロードやストリーミングにはどう対応するのかというと、responseType: "stream"を指定するとOKです。
import axios from "axios";import fs from "node:fs";
const resp = await axios.get("https://example.com/large-file.zip", { responseType: "stream",});resp.data.pipe(fs.createWriteStream("large-file.zip"));fetch が「2回 await」方式を採用したのに対して、axios は「基本は1回 await だけど、レスポンスボディをストリームとして扱いたい場合はオプションを指定する」という形になっていることが分かります。
ky
READMEの先頭に
極楽要求(しなさい)2
と書いてあることで有名(?)なky はどうでしょうか。
import ky from "ky";
// ky では .json() を直接チェーンできるconst data = await ky.get("https://api.example.com/users").json();console.log(data);このように .json() や .text() を直接チェーンできるようになっていて、await は表面上1回だけで済むようになっています。
ストリーミングを扱いたい場合は fetch と同様にできます。
import ky from "ky";
const resp = await ky.get("https://example.com/large-file.zip");const reader = resp.body.getReader();// 以降は fetch と同じレスポンスボディだけに興味があるケース(多くのケースはこれ)に対して便利なAPIを提供しつつ、ストリーミングも自然に扱えるという意味で、個人的には良いAPIだなと感じます。
got
ky と同じ作者による、これまた人気のあるHTTPクライアントライブラリである got も見てみます。
Promise API と
Stream API が用意されています。
import got from "got";
// Promise API: レスポンス全体をメモリに読み込むconst resp = await got("https://api.example.com/users");console.log(resp.body); // レスポンスボディ文字列が出力されるimport { pipeline } from "node:stream/promises";import fs from "node:fs";import got from "got";
// Stream API: チャンクごとに読み込むawait pipeline( got.stream("https://example.com/large-file.zip"), fs.createWriteStream("large-file.zip"),);axios とも ky とも少し違う感じですね。
他の言語の HTTP クライアントはどうしているか
ついでに、他言語のHTTPクライアントライブラリがどのようなAPIになっているのかも確認してみます。
Rust (reqwest)
Rust の reqwest も
fetch と同じ要領で、ヘッダ取得までで1回 await、 ボディ取得で2回目の await が必要です。
// 1回目の await: レスポンスヘッダを取得let resp = reqwest::get("https://api.example.com/data").await?;
// ヘッダにアクセス可能println!("Status: {}", resp.status());
// 2回目の await: ボディを取得let body = resp.text().await?;かなり fetch に似ていますね。
Rustは await が後置なので、レスポンスボディだけに興味がある場合は、以下のようにスマートに書くこともできます。
let body = reqwest::get("https://api.example.com/data") .await? .text() .await?;Python (aiohttp)
Python の aiohttp はおもしろくて、公式ドキュメントの
The aiohttp Request Lifecycleというページでまさにこの問題について解説をしています。そこでは、Pythonで昔からとても人気のあるHTTPライブラリである
requests との対比をすることで、aiohttpの特徴を際立たせています。コード例を引用しつつまとめてみます。
まず、aiohttpでは以下のように、fetch と同じく2回の await に分かれています。
async with aiohttp.ClientSession() as session: # 1回目のawait async with session.get('http://python.org') as resp: # 2回目のawait print(await resp.text())一方で requests は次のようにシンプルです。
resp = requests.get('http://python.org')print(resp.text)この記事をここまで読んできたみなさんなら分かる通り、aiohttp は fetch と同じ思想で設計されています。公式ドキュメントでは次のように説明されています。
aiohttp loads only the headers when
.get()is executed, letting you decide to pay the cost of loading the body afterward, in a second asynchronous operation.
つまり、.get() の時点ではヘッダだけを読み込み、その後ボディの読み込みコストを払うかどうかは開発者が後から決められるようになっているのです。非同期I/Oの利点を最大限に活かすために、ブロッキングのタイミングを明示的に分離しているわけですね。
Go (net/http)
Go は async/await の構文を持たないので少し違って見えますが、本質的には同じです。http.Client.Do() はレスポンスヘッダが届いた時点でリターンし、ボディは io.Reader として提供されます。
resp, err := http.Get("https://api.example.com/data")if err != nil { log.Panic(err)}defer resp.Body.Close()
// この時点でヘッダにアクセス可能fmt.Println("Status:", resp.Status)
// ボディは io.Reader として提供される// io.ReadAll によってレスポンスボディが終わるまでまとめて読み取ることもできるし、// bufio.Reader を使って1行ごとに読み進めていく、もできるbody, err := io.ReadAll(resp.Body)if err != nil { log.Panic(err)}ところで5行目に defer resp.Body.Close() とあります。もしこれを忘れて、なおかつレスポンスボディを読み切らずに放置してしまうと、HTTPレスポンスを中途半端な状態で止めてしまうことになり、TCPコネクションを次のHTTPリクエストのために再利用することができなくなるなどの問題が発生します。
net/http のドキュメントにも「絶対にレスポンスボディをcloseしてね」と書かれているし、
golangci-lintにもこれを検知するリントルール
bodyclose があります。
JavaScriptの fetch でも同じような問題は発生するのでしょうか?つまり、レスポンスボディを読み切らなかったり、明示的なclose処理を忘れたりすると、リソースリークが発生するのでしょうか?
fetch でレスポンスボディを消費しきらなかったらどうなるか?
Fetch 仕様上は GC に頼っても OK
Fetch 仕様の Garbage collection セクションでは、レスポンスボディを消費せずに放置しても、ガベージコレクションによってリソースが解放されることが許容されています。つまり、仕様上はボディを読み切らなくても問題ないことになっています。
Node.js (undici) では GC に頼るべきではない
しかし、Node.js の fetch の内部実装である undici のドキュメントには、
Garbage collection というセクションがあり、次のような警告が書かれています。
Garbage collection in Node is less aggressive and deterministic (due to the lack of clear idle periods that browsers have through the rendering refresh rate) which means that leaving the release of connection resources to the garbage collector can lead to excessive connection usage, reduced performance (due to less connection re-use), and even stalls or deadlocks when running out of connections.
ブラウザには画面描画のリフレッシュレートがあり、その合間がガベージコレクションを実行するのにちょうどいいタイミングになります。しかし Node.js にはそのような「明確なアイドル期間」がないため、GCの実行タイミングが不定期で予測しづらくなります。その結果、レスポンスボディの消費を GC 任せにしてしまうと、コネクションが過剰に使われたり、再利用がうまくいかずパフォーマンスが低下したり、最悪の場合はコネクションが枯渇してデッドロックに陥る可能性があるということです。
そのため、「必ずレスポンスボディを消費するかキャンセルするように」と注意喚起されています。Goと同じですね。
Deno ではリソースリーク検知機能がある
Deno には Resource sanitizer という機能があり、テスト実行時にリソースリークを検知してくれます。もしレスポンスボディを消費もキャンセルもせずに放置すると、テストが失敗します。
import { assertEquals } from "jsr:@std/assert";
Deno.test("fetch without consuming body", async () => { const resp = await fetch("https://example.com"); assertEquals(resp.status, 200); // ⚠️ レスポンスボディを消費し忘れている!});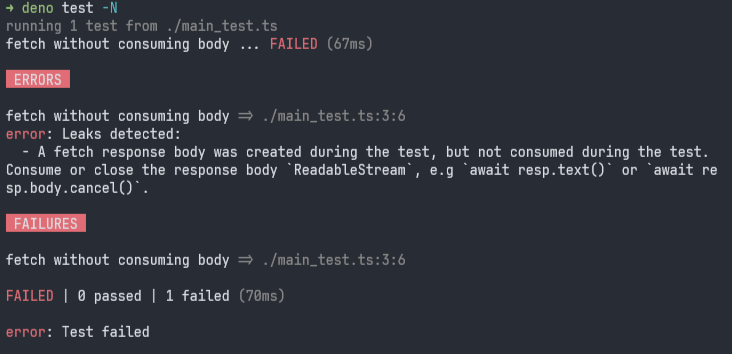
Denoのresource sanitizerが未消費のレスポンスボディを検知している
エラーメッセージで教えてくれているとおり、await resp.text() などしてレスポンスボディを消費しきるようにすれば、このエラーは出なくなります。
import { assertEquals } from "jsr:@std/assert";
Deno.test("fetch without consuming body", async () => { const resp = await fetch("https://example.com"); assertEquals(resp.status, 200); // ✅ レスポンスボディを解放する await resp.body?.cancel();});Explicit Resource Managementとの統合は?
Goだと defer resp.Body.Close() というようにして、respを取得した直後に defer を使って Close の予約をすることができました。直後に置くことで忘れにくくなるというのはもちろん、例えばレスポンスボディを読む前に何かがエラーになってその関数を抜けないといけなくなった、みたいな「異常系」の場合でも、確実に Close が呼ばれるようにできるため、優れた方法です。
JavaScriptでもGoの defer みたいなこと、やりたいですよね?あります。Explicit Resource Management です。2026年1月現在、Chrome, Firefox, Node.js (v24以降)、Deno、Bunで利用可能です。Safariはダメです。
「解放し忘れると良くない」リソース代表として、ファイルディスクリプタがあります。以下のDenoの例では、Explicit Resource Managementを活用することで、確実に file.close() が呼ばれるようにしています。たとえ await file.stat() のところで例外が発生したとしてもです。
async function printStat() { // using がポイント using file = await Deno.open("foo.txt"); const info = await file.stat(); console.log(info);}これを踏まえて考えると、以下のように fetch の戻り値に対してExplicit Resource Managementの仕組みを使えたら嬉しいような気がします。これでレスポンスボディの消費し忘れを防げます。
// こうできたら理想(実際はできない 2026年1月時点)await using resp = await fetch("https://example.com");ただ、これに関してはまだ議論の初期段階で、具体的な話は進んでいないように見えます。今後の進展に期待です。
Discussion: How should streams handle Explicit Resource Management · Issue #1307 · whatwg/streams
まとめ
HTTP ではヘッダが先に届き、ボディは後から(場合によっては永遠に)届き続けます。fetch の2回の await はこの性質をそのまま API に落とし込んだものである、ということでした。
一方で、「ほとんどのケースではボディを全部取得したいだけなのに、毎回2回 await するのは冗長だ」という気持ちもわかります。ky のように .json() をチェーンできるAPIは、よくあるユースケースに対してのシンプルな記法を用意しつつ、レスポンスヘッダとボディを別々に取り扱うというやり方に違和感なく統合されている感じがしました。
HTTPは奥が深いです。この記事で見てきたクライアント側だけではなく、サーバー側も、ライブラリのAPI設計などから透けて見える背後の事情を理解していくのが飽きない楽しさです。またHTTPやWebの仕様について気になることがあったら、掘り下げてみます。
-
ライブコーディング動画を見るのが好きです。過去に
YouTube にあるライブコーディング動画を見て Rust を学ぼう や
【#も読】 ライブコーディング視聴のすすめ(@yusuktan) などを書いています。
-
なんだこのキャッチコピーは、と思って調べてみたら、僕の同僚の